Whitepaper – Escala de Risco Genético
Whitepaper – Escala de Risco Genético
Entenda como as análises de risco genético funcionam
Na Genera, acreditamos que o conhecimento sobre a saúde é transformador, e entender os impactos do seu DNA sobre ela é um dos melhores caminhos para isso. A fim de te ajudarmos nessa jornada, desenvolvemos este material explicativo para que você possa, além de descobrir mais sobre a sua genética, entender como nossas análises e metodologias funcionam.
Para chegarmos aos resultados, analisamos milhares de regiões do DNA. Todas as análises são realizadas em nosso parque tecnológico – considerado um dos mais modernos do Brasil. Os dados gerados durante este processo são, então, comparados com nosso banco de dados.
Parte I
O que procuramos?
Parte I
O que procuramos?
O DNA (sigla em inglês para “ácido desoxirribonucleico”) é a molécula que fica dentro de praticamente todas as células que compõem nosso corpo e contém em si toda a informação genética que molda e gerencia cada um de nós. São essas informações que definem, regulam e influenciam como somos, seja em termos de características físicas, como altura, cor dos olhos e cabelo, seja em traços de personalidade e predisposição a doenças ou no controle do metabolismo e funcionamento dos órgãos. Todo ser humano recebe metade do seu DNA por parte de mãe e a outra metade por parte de pai.
Algumas regiões do DNA se alteraram mais que outras no decorrer das gerações e costumam ser utilizadas como marcadores genéticos. No caso da Escala de Risco Genético, analisamos os SNPs (sigla em inglês para “Polimorfismo de Nucleotídeo Único”). Estes marcadores em específico consistem em mutações de apenas um nucleotídeo, que são as quatro letras que compõem o DNA (A, T, C ou G). Portanto, um SNP é uma variação de um par de letras da sequência genética. Por exemplo, algumas pessoas podem ter uma sequência ATTC enquanto outras têm AGTC. Essa troca da letra T por G é um SNP.


Alguns SNPs estão associados a maiores ou menores riscos de uma pessoa desenvolver certas doenças ao longo da vida. Ao analisarmos um conjunto desses SNPs em vários genes diferentes ao longo de todo o genoma, podemos chegar a uma estimativa de risco genético individual para uma doença.
Embora existam doenças causadas por mutações em um único gene (chamadas de doenças monogênicas), como a hemocromatose hereditária, a grande maioria das condições comuns são influenciadas por uma combinação de vários genes. Nesses casos, a análise de diferentes SNPs em vários genes permite um cálculo mais preciso e assertivo.

Parte II
Como é feito o cálculo?
Parte II
Como é feito o cálculo?
1. Base da análise
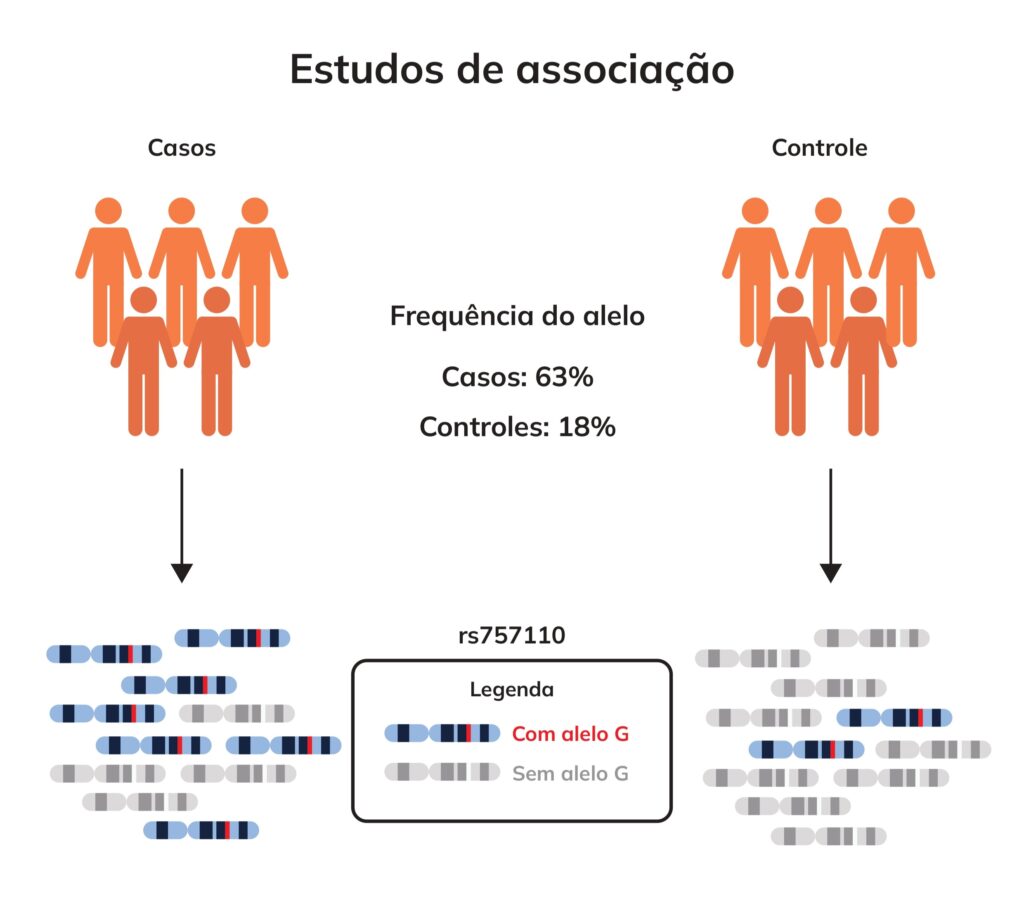
Após o processamento de sua amostra, procuramos em seus dados por algumas variantes específicas que, segundo os Estudos Genômicos de Associação (do inglês, Genome Wide Association Studies, ou GWAS), representam um certo impacto na chance de se desenvolver as doenças calculadas. Cada uma dessas variantes causa, de maneira geral, um pequeno impacto (também chamado tamanho de efeito), mas, quando levamos em conta dezenas ou centenas delas, o poder preditivo do cálculo aumenta.
Os Estudos Genômicos de Associação são uma extensa área de investigação na qual o DNA de milhares de voluntários é analisado em busca de padrões que possam ser relacionados com alguma característica alvo do estudo, por exemplo, a doença de Alzheimer. Ou seja, os genomas tanto de pessoas afetadas pela doença quanto de não afetadas são analisados e comparados de modo a encontrar variantes que estejam significativamente mais presentes em um dos grupos. Essas variantes são, então, propostas como fatores de risco ou proteção contra a doença, e um tamanho de efeito é calculado e atribuído a cada uma.
2. Processamento
Mais especificamente, o processamento da amostra pode ser dividido nas etapas de faseamento, imputação e cálculo do risco.
O faseamento é o processo de identificação da origem genética paterna ou materna dos alelos. Esta etapa é mais simples quando a genotipagem é feita com o trio familiar: mãe, pai e filho. No entanto, também é possível estimar a origem através de métodos estatísticos.
Após o faseamento, inicia-se a etapa de imputação, que utiliza a sequência de alelos adquiridas da amostra como base para estimar as posições especificas do genoma que não foram diretamente genotipadas. Podemos comparar a imputação a um jogo de forca: imagine a palavra “G – E – N – É – _ – I – C – A”. Baseando-se nas letras anteriores e posteriores, deduzimos que a letra ausente é “T”, formando “GENÉTICA”. Assim, a imputação depende do faseamento, pois a origem dos alelos é fundamental para estimar os outros genótipos.
Além disso, para garantir a melhora no processo de faseamento e imputação, utilizamos um “painel de referência”, que contém amostras com origens conhecidas e variantes nas posições de interesse para imputação. O painel inclui amostras com diferentes ancestralidades, que são representativas para a população analisada.
Depois de adquirir as informações de quantas e quais variantes estão no seu DNA, juntamente com o tamanho do efeito de cada uma delas, utilizamos modelos matemáticos que unem essas informações em um único número. Adicionalmente, esse valor de risco é ajustado por machine learning conforme a análise de ancestralidade de cada amostra. Ou seja, é realizado um ajuste do risco calculado das variáveis, garantindo que os resultados reflitam de maneira adequada a ancestralidade global.
O valor de risco é então comparado com as médias do nosso banco de dados e com as estatísticas de incidência das doenças na população, para enfim chegar ao resultado final de risco, que é mostrado na página de resultados.
3. Resultados
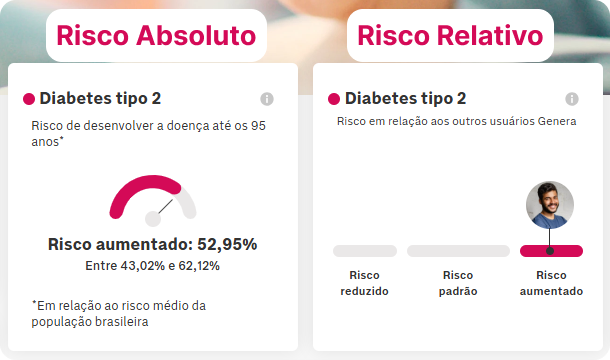
Os resultados indicam o risco absoluto e o risco relativo. O primeiro apresenta o risco independente da comparação com qualquer outro grupo, através de arquivos de incidência que indicam o risco pela faixa de idade. Já o segundo, é o risco de um indivíduo em relação a um banco de dados. A ferramenta de cálculo para risco absoluto foi desenvolvida pela equipe de Pesquisa e Desenvolvimento da Genera.

Parte III
E os meus dados?
Parte III
E os meus dados?
Tão importante quanto entender como desenvolvemos nossos métodos e chegamos aos resultados da Escala de Risco Genético, é entender como cuidamos de seus dados. Na Genera, a segurança dos seus dados é de extrema importância e buscamos ser transparentes em relação a isso.
Suas informações genéticas são mantidas em nossos bancos de dados de forma segura. Nenhum acesso exterior a elas é permitido e não há nenhuma comercialização a terceiros das mesmas. Nossa política de privacidade, ponto a ponto, pode ser acessada aqui.
É importante ressaltar que apenas clientes que tiveram seus resultados processados após a implementação da nova metodologia, terão acesso aos novos resultados do painel Escala de Risco Genético.
Referências e leituras adicionais
Referências e leituras adicionais
LI, Yun et al. Genotype imputation. Annual review of genomics and human genetics, v. 10, n. 1, p. 387-406, 2009. https://doi.org/10.1146/annurev.genom.9.081307.164242.
CHOUDHURY, Parichoy et al. ICARE: an R package to build, validate and apply absolute risk models. Plos One, [S.L.], v. 15, n. 2, p. e0228198, 5 fev. 2020. Public Library of Science (PLoS). http://dx.doi.org/10.1371/journal.pone.0228198.
MARNETTO, Davide et al. Ancestry deconvolution and partial polygenic score can improve susceptibility predictions in recently admixed individuals. Nature Communications, [S.L.], v. 11, n. 1, p. 1628, 2 abr. 2020. Springer Science and Business Media LLC. http://dx.doi.org/10.1038/s41467-020-15464-w